深度学习复习课
0. 题型
| 题型 | 数量 | 分值 |
|---|---|---|
| 简答题 | 4 | 60 |
| 设计题 | 2 | 25 |
| 未知题型 | 1 | 15 |
老师对最后的题目讳莫如深,“你只要上课听了,还是能拿一点分的”。
乐。
1. 提纲
第二章
- 掌握随机梯度下降算法
- 掌握批量梯度下降算法
- 理解正则化(L1,L2)
- 掌握Dropout思想、处理流程等
- 掌握常用定理:NFL、丑小鸭、奥卡姆剃刀等
第三章
- 掌握Logistic回归、Softmax回归
- 掌握各种常见的损失函数公式以及针对具体的应用场景,如平方损失、交叉熵损失等
- 理解经验风险与结构风险
第四章
- 掌握几种常见的激活函数(Sigmoid、ReLU)优缺点
- 理解前馈神经网络的基础知识
第五章
- 掌握卷积神经网络的特点(对比全连接网络)
- 卷积网络:卷积核、特征图、颜色通道数
- 汇聚层的作用
- 常见典型CNN卷积结构的参数计算(例如卷积层的参数量、链接数、输出图大小等)
- 掌握残差网络(工作原理、公式等)
第六章
- RNN公式的表达
- RNN中出现的梯度消失和梯度爆炸问题
- 对应的解决办法
- 掌握序列到序列的模型(同步和异步)
- 具体应用(同步和异步-Sentiment Analysize)
- 公式表达
- 优缺点
- 掌握LSTM
- 三个门的作用与意义
- LSTM对比RNN的优缺点
- ‘输入与输出
- ’LSTM可以解决梯度消失问题,类似残差网络的处理方法
- 掌握GRU
- 对比LSTM有哪些改进
- ‘GRU的公式
第七章 网络优化
- 学习率的改进
- 学习率衰减-看看就行
- 周期性调整-不必看公式
- 重点掌握:自适应调整:Adagrad, Adadelta, RMSProp
- 三种方法掌握公式与原理,重点是公式
- 梯度优化
- 动量法
- Nesterov加速梯度
- Adam算法
- 梯度截断
- 高低维度情况下的网络优化
逃离鞍点
- 数据归一化三种方法
- ’取出相关维度的相关性-白化
- 掌握批量归一化与层归一化(定义、方法、具体操作方法)
- 丢弃法(Dropout)
第八章
- 掌握注意力模型
- 意义-为啥要注意力模型
- 公式
- 处理流程等
- 掌握自注意力模型
- 意义-重点掌握、教之前的提升、KQV计算等
- 公式
- 处理流程
- 掌握Transformer(结构、技术等)
第十四章
- 强化学习的五要素
- 第五要素:
策略
- 第五要素:
- 两个值函数:状态值函数、状态-动作值函数
- 掌握策略迭代算法、值迭代算法、SARSA算法以及Q-Learning算法
蒙特卡洛采样
2.机器学习概述
机器学习三要素
模型
线性模型
广义线性模型
学习准则
在线性回归模型中,下面的所有损失函数
都是平方损失函数。
期望风险是对现实情况而言的
但是真实的数据分布无法获得,只能通过经验风险近似:
在使用经验风险近似期望风险时,会产生泛化错误。减小泛化错误的需要优化和正则化(损害优化,防止过拟合)两种手段。
结构风险在经验风险的基础上增加了正则化项,结构风险最小化可以解决(缓解)过拟合问题。
优化方法
(批量)梯度下降、随机梯度下降、小批量梯度下降、早停
(批量)梯度下降
批量梯度下降法在每次迭代时需要计算每个样本上损失函数的梯度并求和(目标函数是整个训练集上的风险函数)。当训练集中的样本数量𝑁 很大时,空间复杂度比较高,每次迭代的计算开销也很大。
随机梯度下降
批量梯度下降法相当于是从真实数据分布中采集𝑁 个样本,并由它们计算出来的经验风险的梯度来近似期望风险的梯度.为了减少每次迭代的计算复杂度,我们也可以在每次迭代时只采集一个样本,计算这个样本损失函数的梯度并更新参数,即随机梯度下降法
批量梯度下降和随机梯度下降之间的区别在于,每次迭代的优化目标是对所有样本的平均损失函数还是对单个样本的损失函数.由于随机梯度下降实现简单,收敛速度也非常快,因此使用非常广泛.随机梯度下降相当于在批量梯度下降的梯度上引入了随机噪声.在非凸优化问题中,随机梯度下降更容易逃离局部最优点.
小批量梯度下降*

正则化方法
正则化(Regularization)是一类通过限制模型复杂度,从而避免过拟合,提高泛化能力的方法,比如引入约束、增加先验、提前停止等.
正则化的方法有如下:
- L范数正则化
- 权重衰减
- 提前停止
- 丢弃法
- 数据增强
- 标签平滑
L范数正则化
本质上是引入一个约束,作为惩罚。这样在优化的时候,不能只看目标函数,还得考虑引入的惩罚(正则化项)。得治治
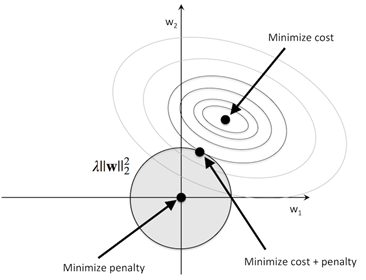
L1正则化无论权重大小,施予相同的惩罚,较小的权重就会变成0. 使得L1正则化最大的作用是使大量参数变为0,将模型稀疏化。
L2正则化对大权重惩罚很重,小权重惩罚很轻。引入到式子里的一般是二范数的平方方便计算(如上图)。
Dropout
详细参见网络优化-Dropout部分
常用定理
没有免费午餐定理(NFL):对于基于迭代的最优化算法,不存在某种算法对所有问题(有限的搜索空间内)都有效.如果一个算法对某些问题有效,那么它一定在另外一些问题上比纯随机搜索算法更差.也就是说,不能脱离具体问题来谈论算法的优劣,任何算法都有局限性.必须要“具体问题具体分析”
奥卡姆剃刀(Occam’s Razor)原理:“如无必要,勿增实体”.奥卡姆剃刀的思想和机器学习中的正则化思想十分类似:简单的模型泛化能力更好.如果有两个性能相近的模型,我们应该选择更简单的模型.因此,在机器学习的学习准则上,我们经常会引入参数正则化来限制模型能力,避免过拟合.
丑小鸭定理:“丑小鸭与白天鹅之间的区别和两只白天鹅之间的区别一样大”.因为世界上不存在相似性的客观标准,一切相似性的标准都是主观的.如果从体型大小或外貌的角度来看,丑小鸭和白天鹅的区别大于两只白天鹅的区别;但是如果从基因的角度来看,丑小鸭与它父母的差别要小于它父母和其他白天鹅之间的差别.这里的丑小鸭是指幼年白天鹅
3. 线性模型
Logistic 回归
西瓜书中叫对数几率回归,是一种常用的二分类问题模型
这是一个平平无奇的线性模型:
引入激活函数进行非线性变换,将输出映射到
实际上输出的
损失函数使用交叉熵:
其中
求导结果为输入与一阶损失的乘积,因此梯度下降法更新如下:
Softmax回归
多分类的Logistic回归,是Logistic更一般的形式

在风险函数中加入正则化来约束其参数.不加入正则化项限制权重向量的大小, 可能造成权重向量过大, 产生上溢.

分析为什么平方损失函数不适用于分类问题.
分类问题中的标签,是没有连续的概念的。每个标签之间的距离也是没有实际意义的,所以预测值和标签两个向量之间的平方差这个值不能反应分类这个问题的优化程度。比如分类 1,2,3, 真实分类是1, 而被分类到2和3错误程度应该是一样的, 但是平方损失函数的损失却不相同.
①目标函数不一致:分类问题的目标是将样本正确分类到不同的类别中,而不是预测一个连续值。平方损失函数的目标是最小化预测值与真实值之间的平方差异,这与分类问题的目标不一致。
②异常值敏感性:平方损失函数对异常值非常敏感。在分类问题中,异常值通常表示样本的错误分类,这意味着对异常值的错误分类会导致非常高的损失。分类问题中的异常值更常见,因为分类问题涉及到预测离散的类别标签,而异常值可能导致较大的误差。
③梯度消失:平方损失函数在分类问题中容易出现梯度消失的问题。由于分类问题的输出是一个概率或类别标签,使用平方损失函数时,梯度可能变得非常小,使得模型难以学习或收敛。
④不可导性:在分类问题中,常用的激活函数(如sigmoid、softmax)通常与平方损失函数不兼容。这是因为这些激活函数产生的输出不是连续的,而平方损失函数对于连续的输出是可导的。因此,在分类问题中使用平方损失函数可能会导致不可导的情况,使得无法使用常规的优化算法进行训练。




4. 神经网络
激活函数
一个合格的激活函数应该具有以下性质:
- 连续可导
- 简单、方便计算
- 值域在一个合适的区间
Sigmoid系列
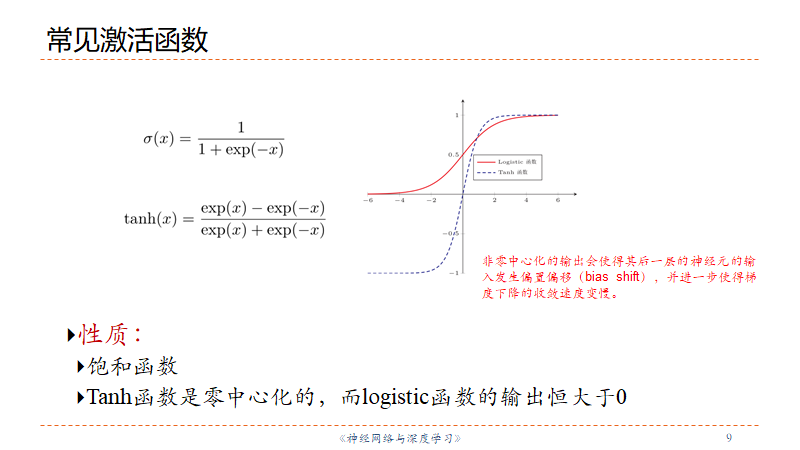
两者都是simoid型函数,具有饱和性:
- 计算开销大
- 输出平滑,没有跳跃值
- 处处可导
- 适用于概率
- 梯度消失
- 以0/不以0为中心
ReLU系列
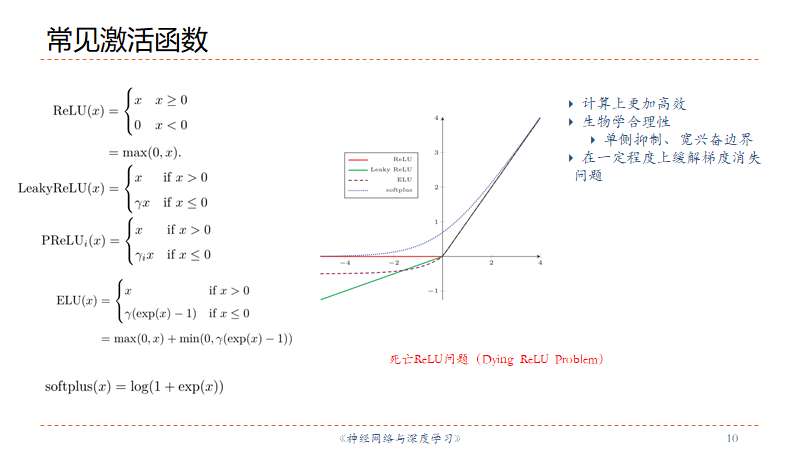
优点
- 计算开销小,只有简单的加乘
- 生物合理性:单侧抑制
- 左侧饱和,x>0时导数为1,缓解梯度消失
- 加速梯度下降的收敛速度
缺点
非0中心化,给后层带来偏置
死亡ReLU问题:一次不恰当的更新,就永远不能被激活(ELU可以解决)
前馈神经网络
输入层不算入网络层数,网络层数指的是隐层数量

通用近似定理
根据通用近似定理,对于具有线性输出层和至少一个使用“挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其隐藏层神经元的数量足够,它可以以任意的精度来近似任何从一个定义在实数空间中的有界闭集函数。
神经网络可以作为一个“万能”函数来使用,可以用来进行复杂的特征转换,或逼近一个复杂的条件分布。
5. CNN
FCN处理图像有如下问题:
- 参数太多
- 局部不变特性
自然图像中的物体都具有局部不变性特征,比如尺度缩放、平移、旋转等操作不影响其语义信息.而全连接前馈网络很难提取这些局部不变性特征
CNN特点
CNN天生就适合处理图像:
- 局部连接:局部连接会大大减少网络的参数。在处理图像这样的高维度输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的。让每个神经元只与输入数据的一个局部区域连接,该连接的空间大小叫做神经元的感受野,它的尺寸是一个超参数,其实就是滤波器的空间尺寸。
- 权值共享:在卷积层中使用参数共享是用来控制参数的数量。每个滤波器与上一层局部连接,同时每个滤波器的所有局部连接都使用同样的参数,此举会同样大大减少网络的参数。
- 空间或时间上的次采样:它的作用是逐渐降低数据的空间尺寸,这样的话就能减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合。
这些特性使得卷积神经网络具有一定程度上的平移、缩放和旋转不变性.和前馈神经网络相比,卷积神经网络的参数更少
卷积层
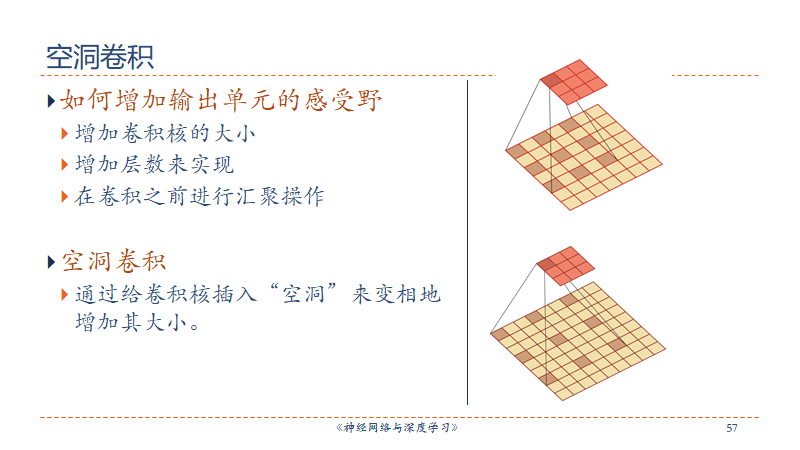
卷积核大小:卷积核定义了卷积的大小范围,在网络中代表感受野的大小,二维卷积核最常见的就是 3*3 的卷积核。一般情况下,卷积核越大,感受野越大,看到的图片信息越多,所获得的全局特征越好。但大的卷积核会导致计算量的暴增,计算性能也会降低。(大到极致就是FCN)
步长:卷积核的步长代表提取的精度, 步长定义了当卷积核在图像上面进行卷积操作的时候,每次卷积跨越的长度。对于size为2的卷积核,如果step为1,那么相邻步感受野之间就会有重复区域;如果step为2,那么相邻感受野不会重复,也不会有覆盖不到的地方;如果step为3,那么相邻步感受野之间会有一道大小为1颗像素的缝隙,从某种程度来说,这样就遗漏了原图的信息。
填充:卷积核与图像尺寸不匹配,会造成了卷积后的图片和卷积前的图片尺寸不一致,为了避免这种情况,需要先对原始图片做边界填充处理。
特征映射(Feature Map)为一幅图像(或其他特征映射)在经过卷积提取到的特征,每个特征映射可以作为一类抽取的图像特征.为了提高卷积网络的表示能力,可以在每一层使用多个不同的特征映射,以更好地表示图像的特征.
在输入层,特征映射就是图像本身.如果是灰度图像,就是有一个特征映射,输入层的深度𝐷 = 1;如果是彩色图像,分别有RGB 三个颜色通道的特征映射,输入层的深度𝐷 = 3.
卷积层输入特征映射
卷积输出图的大小:
连接数: 参数个数 ×输出的特征图平面大小
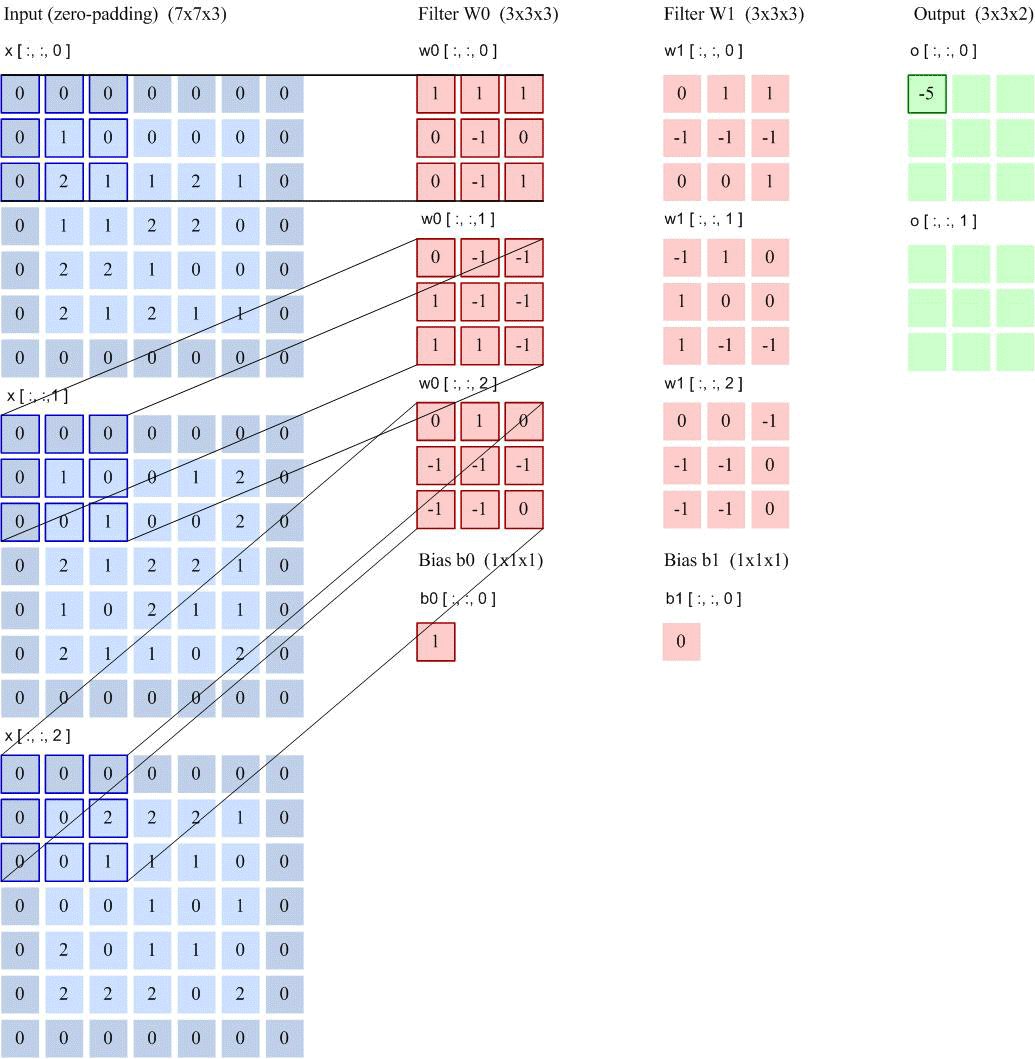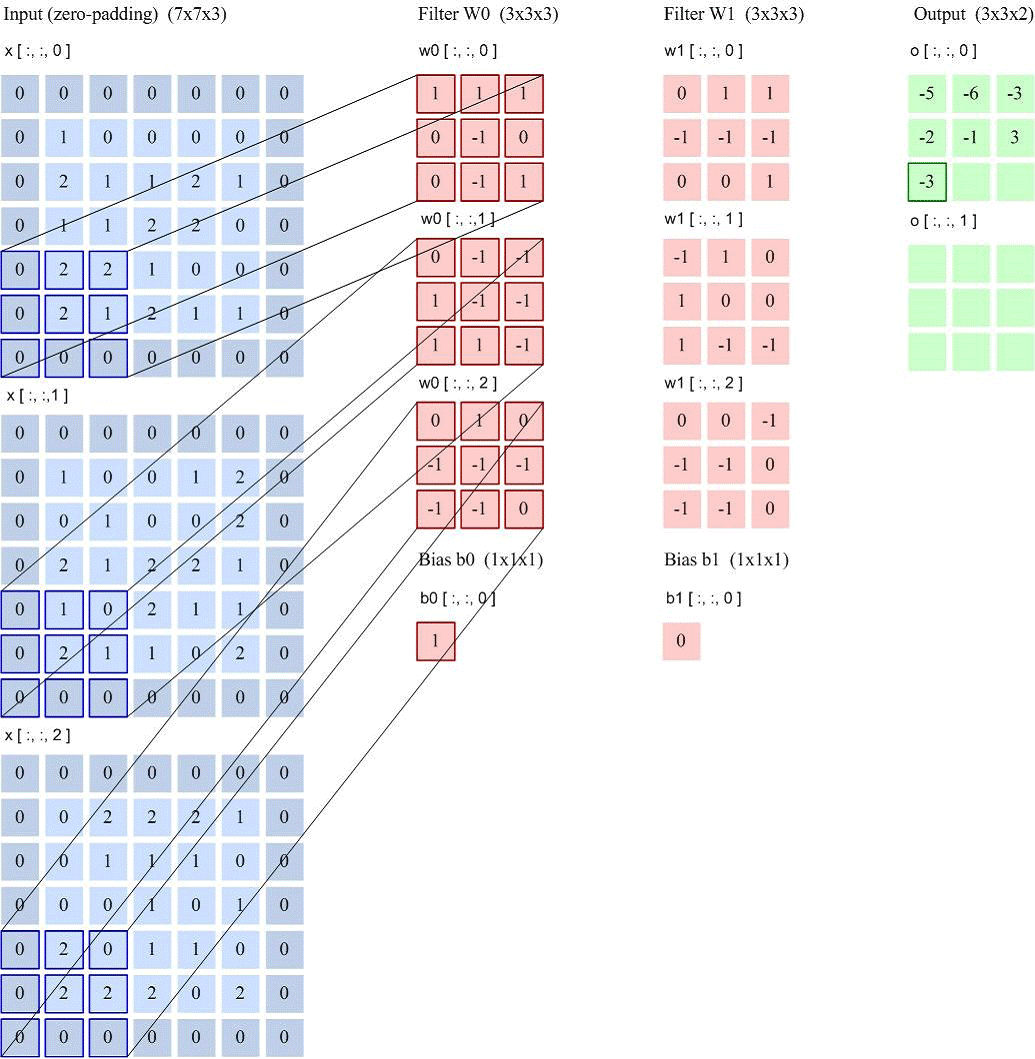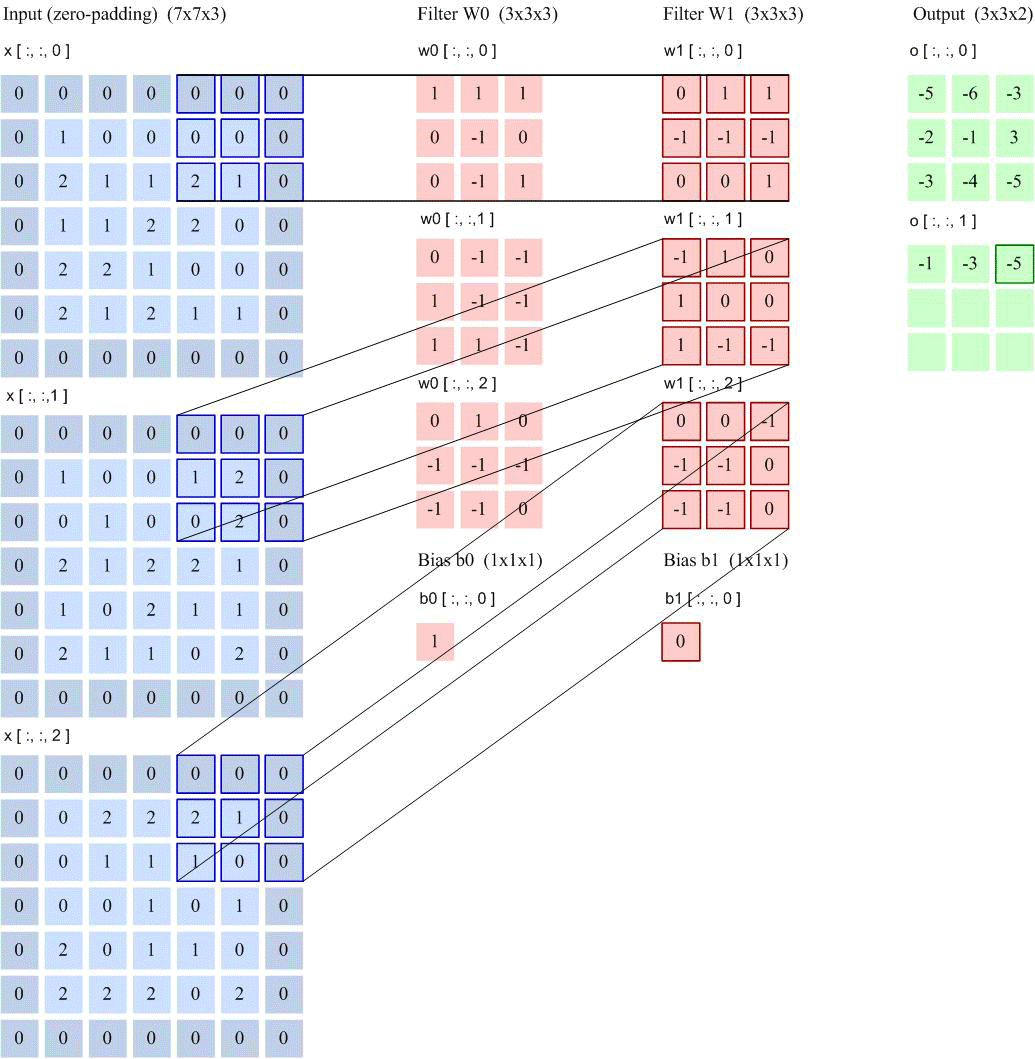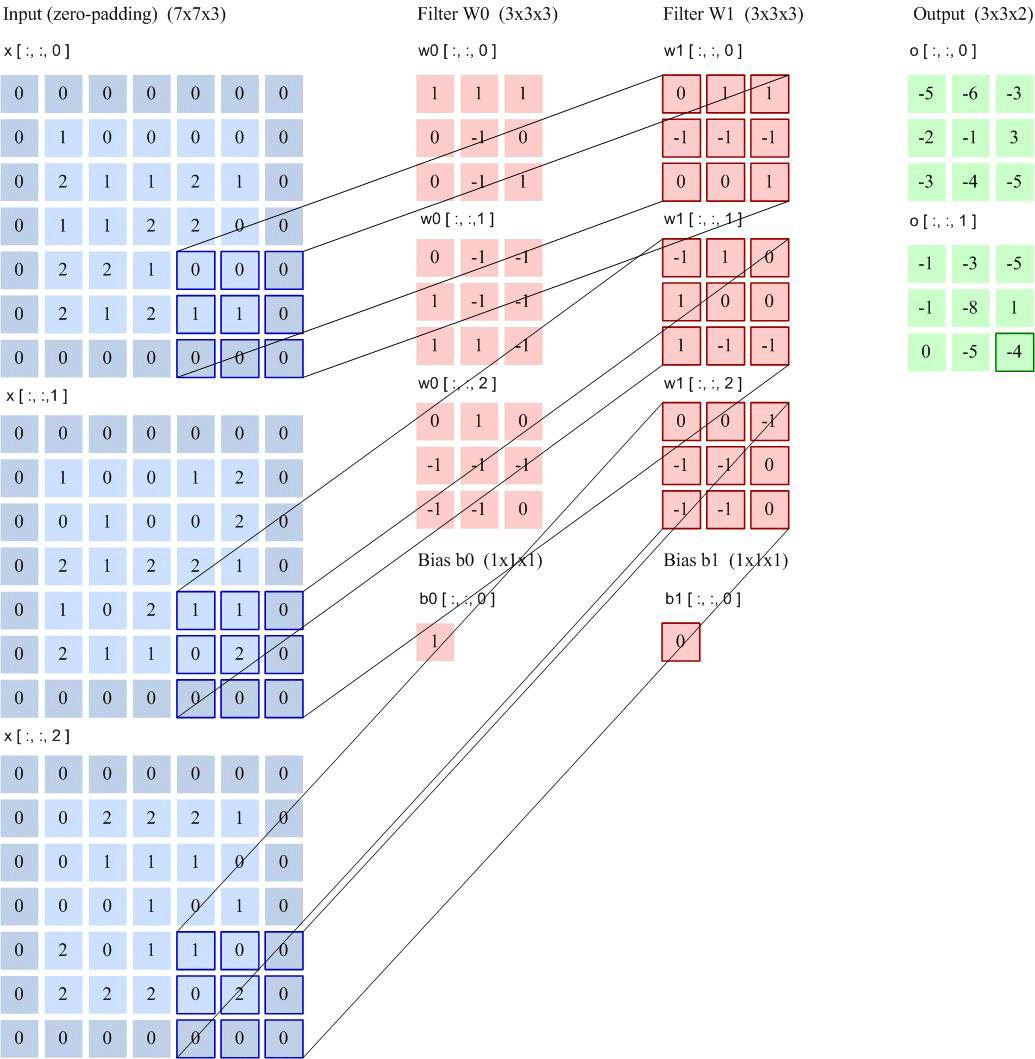
以LeNet-5为例进行计算: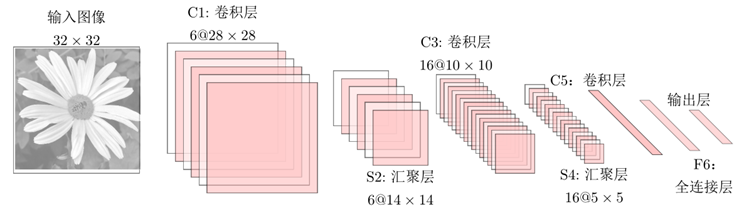

汇聚层
作用:
- 减少计算量和参数数量,使得模型更容易训练;
- 降低特征图的分辨率,减少过拟合;
- 提取更为重要的特征,因为汇聚层只选择最大值或平均值,这些值往往包含更多的信息
残差网络
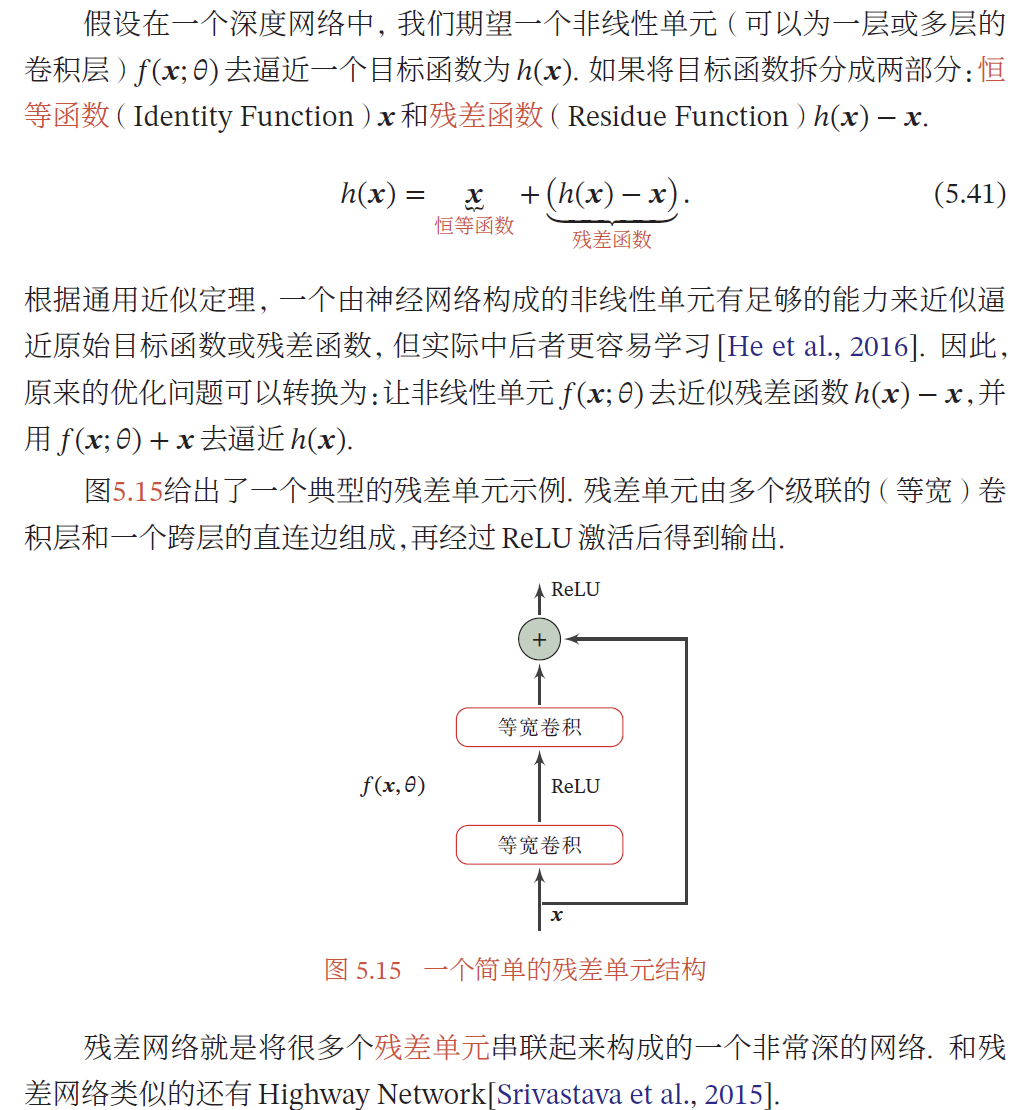
题目
分析卷积神经网络中用1 × 1的卷积核的作用.
解答
- 降维(减少参数)
在Inception网络中
使用 1 × 1 的卷积来减少特征映射的深度- 升维(使用最少的参数拓宽维度)
如下的ResNet网络结构图
右侧最后一层使用 1 × 1 × 256 的卷积核来将输出的64维提升到 256 维
且只需要 64_1_1*256 个参数- 跨通道信息交互
实现升维和降维的操作,其实就是不同通道之间的线性组合,这就是跨通道信息交互- 增加非线性特性
每一个卷积操作之后会添加一个非线性激活函数,使用 1 × 1 的卷积核可以在保持特征图尺度不变的情况下增加非线性特性


6. 注意力机制
由于优化算法和计算能力的限制,神经网络要想达到通用近似能力,网络不能太复杂。
Attention
意义
解决长序列语义丢失与输入贡献度分配问题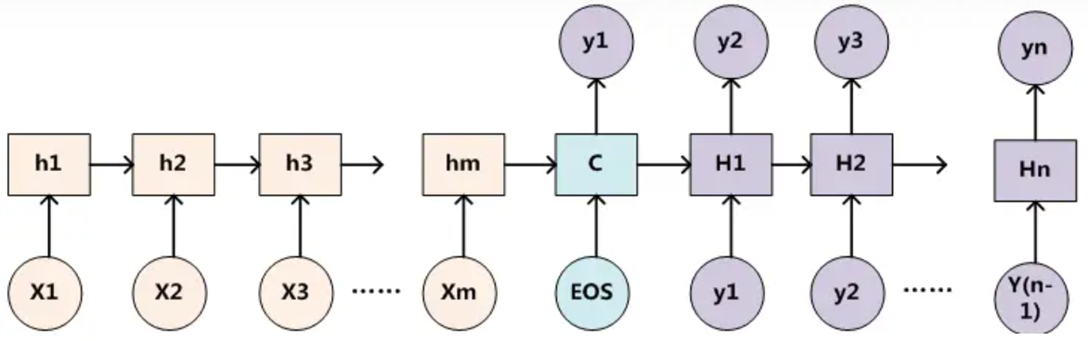
- Source 经过 Encoder,生成中间的语义编码 C。
- C 经过 Decoder 之后,输出翻译后的句子。在循环神经网络中,先根据 C 生成 y1,再基于(C,y1)生成 y2,依此类推。
传统的循环神经网络中,y1、y2 和 y3 的计算都是基于同一个 C. 然而,可能并不是最好的方案,因为 Source 中不同单词对 y1、y2 和 y3 的影响(贡献)是不同的。
从语义编码C入手,注意力机制使其在每个时刻根据编码器的输入自适应变化,从而对下个模块(比如:解码器)的输出产生影响。AIM:解决每个输入贡献度问题
公式
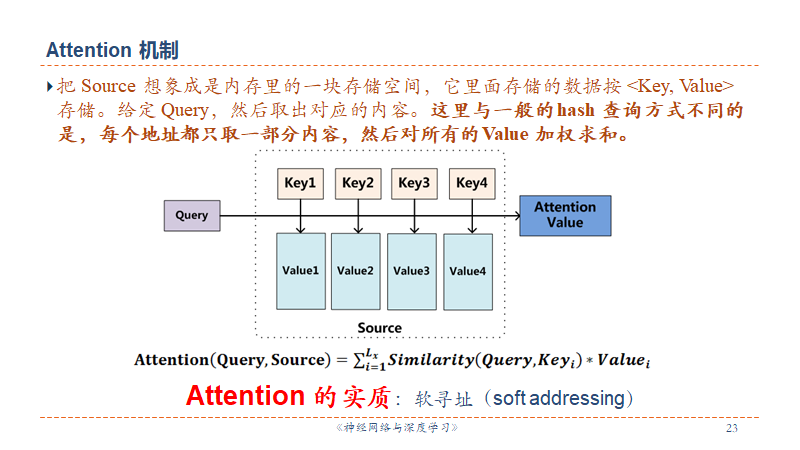
流程
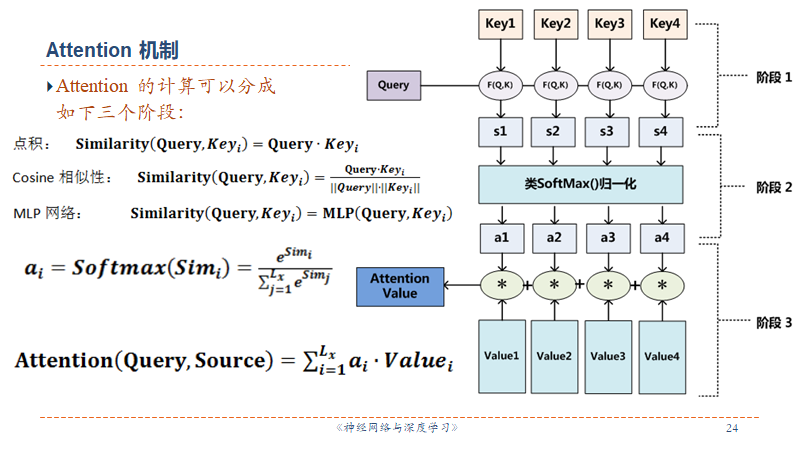
- F(Q,K)计算相似度,可选用Dot Product, Cosine, MLP
- F 的输出再经过 Softmax 进行归一化就得到注意力分配概率
- 最后根据
计算输入信息的加权平均,得到注意力值 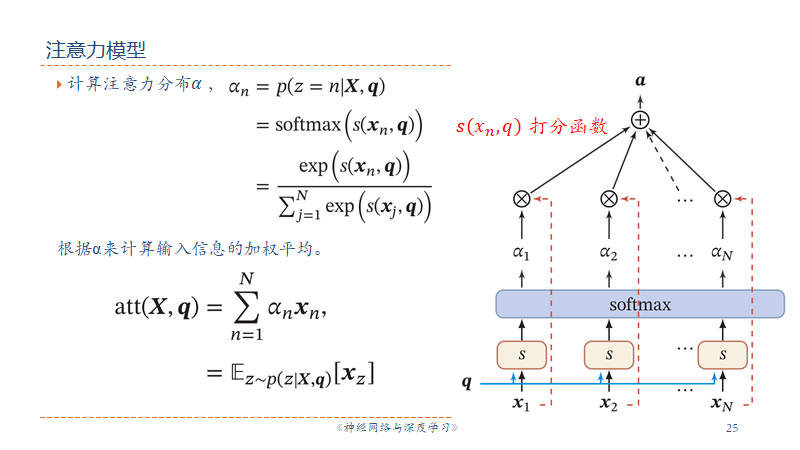
这张图与之前的一张没什么不同,更简洁直观了。需要注意SoftMax之后的加权平均,可以写成随机变量的期望形式。
变体
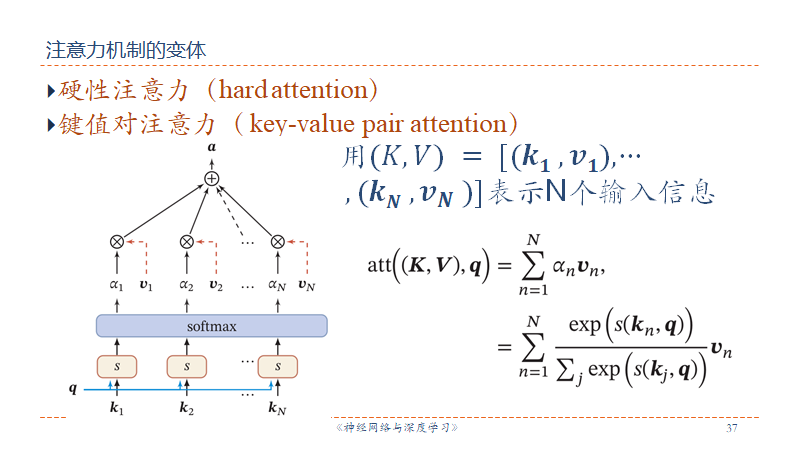
李宏毅讲的就是这种键值对注意力机制。

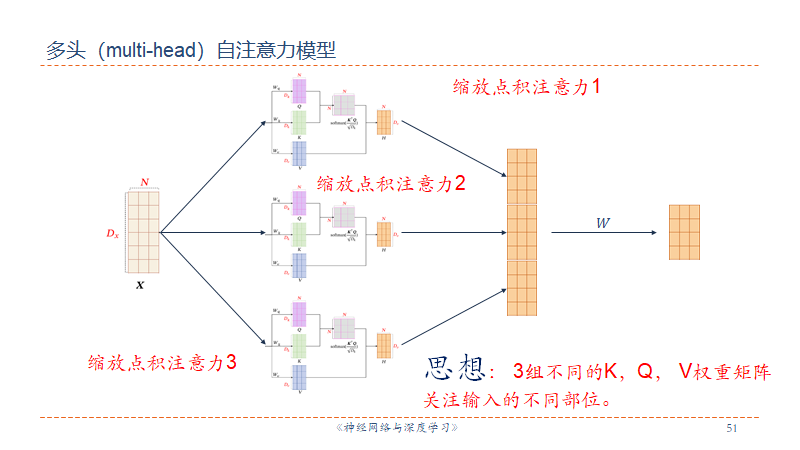
多头注意力机制。
Self-Attention
意义
引入 Self Attention 机制,顾名思义,指的是 Source 内部元素之间或者 Target 内部元素之间发生的 Attention 机制,也可以理解为 Source = Target 这种特殊情况下的Attention 机制,具体计算过程和 Soft Attention 是一样的
KQV模式
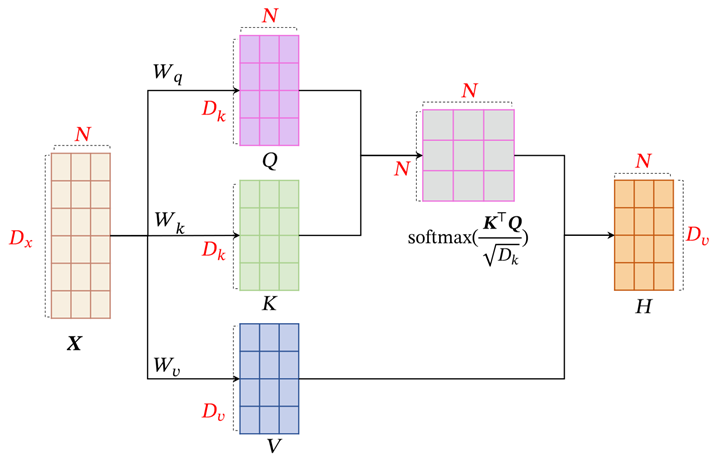
与李宏毅讲的一毛一样。
SoftMax中的处理稍有不同,分母是一个常数。
流程

- 计算
向量,这三个向量分别由输入的 与对应的权重矩阵 相乘得到 - 计算self-attention,由Query与Key点乘(dot product)得到,该分数值决定了当我们再某个未知encode一个词时,对输入句子其它部分的关注程度
- 将点乘结果除以一个常数(一般
),再把结果softmax,得到的结果时每个词对当前位置词的相关性大小(与自己最大) - 把Value与Softmax得到的值相乘相加,得到的结果就是self-attention再当前节点的值(缩放点积注意力)
Transformer
结构
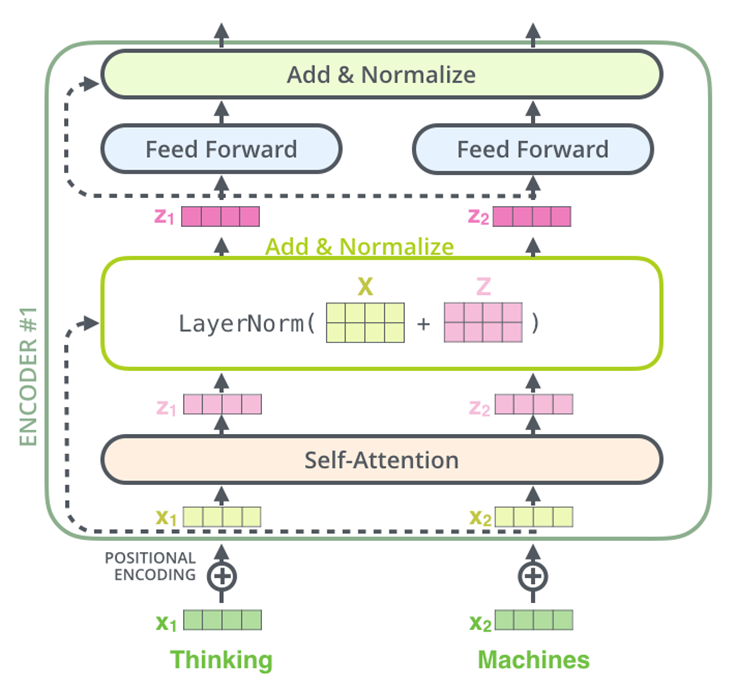
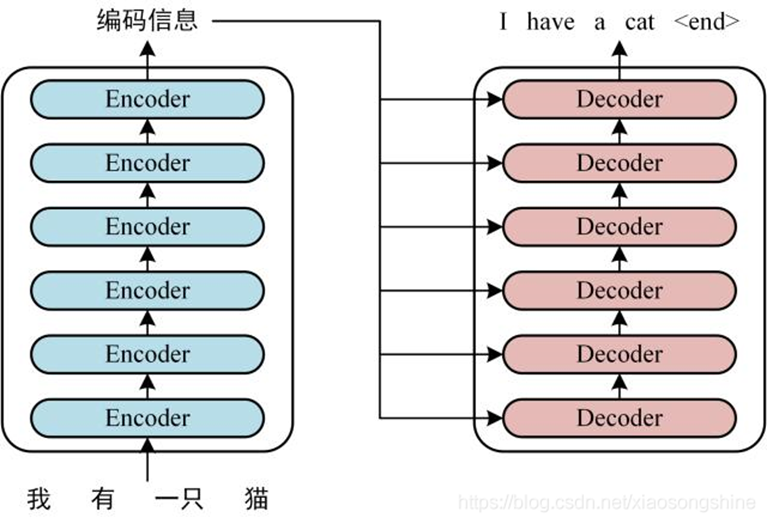
transformer采用encoder-decoder架构,如下图所示。Encoder层和Decoder层分别由6个相同的encoder和decoder堆叠而成,模型架构更加复杂。其中,Encoder层引入了Muti-Head机制,可以并行计算,Decoder层仍旧需要串行计算。
炫技
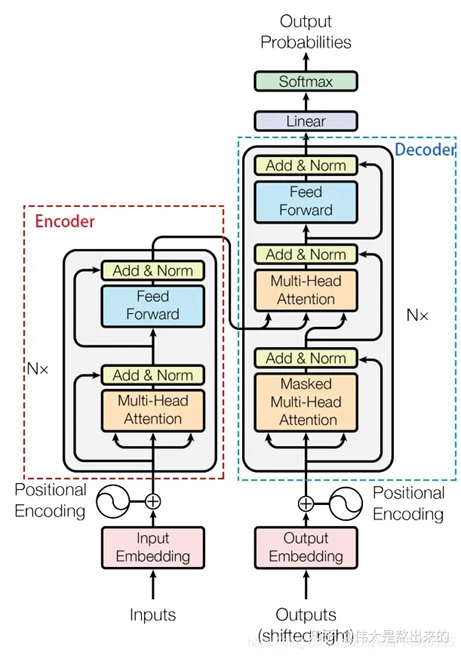
Self-attention: 计算句子中的每个词都和其他词的关联,从而帮助模型更好地理解上下文语义
Multi-head attention: 每个头关注句子的不同位置,增强了Attention机制关注句子内部单词之间作用的表达能力
Transformer为什么需要进行Multi-head Attention ?
原论文中说到进行Multi-head Attention的原因是将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息,最后再将各个方面的信息综合起来。直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。前馈神经网络FFN: 为encoder引入非线性变换,增强了模型的拟合能力
Decoder接受output输入的同时接受encoder的输入,帮助当前节点获取到需要重点关注的内容
Feed Forward Network: 每一层经过attention之后,还会有一个FFN,这个FFN的作用就是空间变换。FFN包含了2层linear transformation层,中间的激活函数是ReLu。FFN的加入引入了非线性(ReLu激活函数),变换了attention output的空间, 从而增加了模型的表现能力。把FFN去掉模型也是可以用的,但是效果差了很多
层归一化(Layer Normalization): 规范优化空间,加速收敛
Positional Encoding: 位置信息编码位于encoder和decoder的embedding之后,每个block之前。它非常重要,没有这部分模型就无法运行。Positional Encoding是transformer的特有机制,弥补了Attention机制无法捕捉sequence中token位置信息的缺点,使得每个token的位置信息和它的语义信息(embedding)充分融合,并被传递到后续所有经过复杂变换的序列表达中去。
Mask 机制: mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。其中,padding mask 在所有的 scaled dot-product attention 里面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 里面用到。
Padding mask:每个批次输入序列长度或许不同,需要对输入序列进行对齐。
- 具体来说,给在较短的序列后面填充 0;
- 如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃
- attention机制不应该关注这些,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0
Sequence mask:使得 decoder 不能看见未来的信息。对于一个序列,在 time_step 为 t 的时刻,解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此需要把 t 之后的信息隐藏起来。产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上
Residual Network 残差网络:
网络退化现象:在神经网络可以收敛的前提下,随着网络深度的增加,网络表现先是逐渐增加至饱和,然后迅速下降。
在transformer模型中,encoder和decoder各有6层,为了使当模型中的层数较深时仍然能得到较好的训练效果,模型中引入了残差网络。
解决网络过深带来的网络退化问题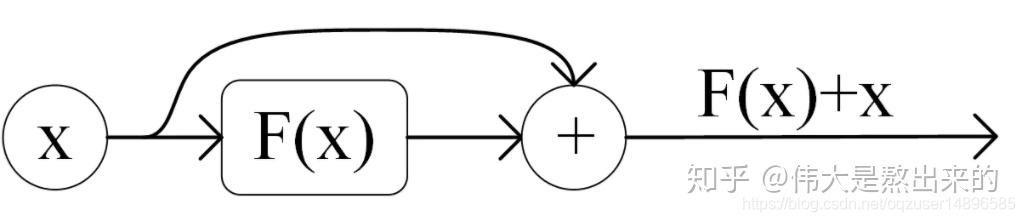
好处都有啥
Seq2Seq模型的两个痛点:
- 序列过长,语义消失问题
- 位置信息丢失


- 首先改进了上面两个缺点,做法为: 1-残差结构,2-位置编码
- 多头注意力能提取更多的信息
- encoder层的多头注意力可以并行计算
- self-attention模块让源序列和目标序列首先“自关联”起来,使得源序列和目标序列自身的embedding表示所蕴含的信息更加丰富
- FFN层也增强了模型的表达能力
- …

7. RNN
SRN
前馈神经网络层与层之间连接,层内不连接(不循环);同时输入与输出都是固定的长度,不能处理变长的序列数据。
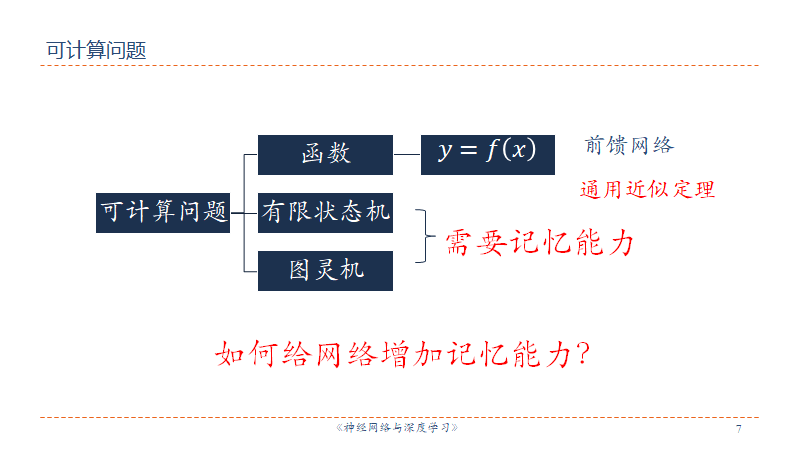
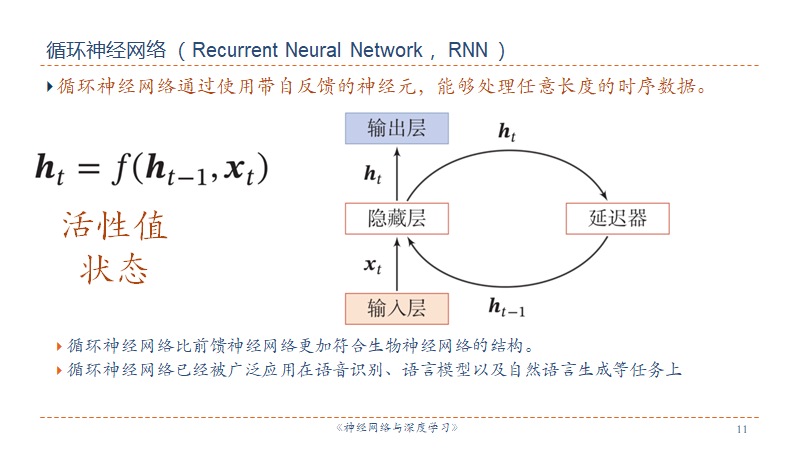
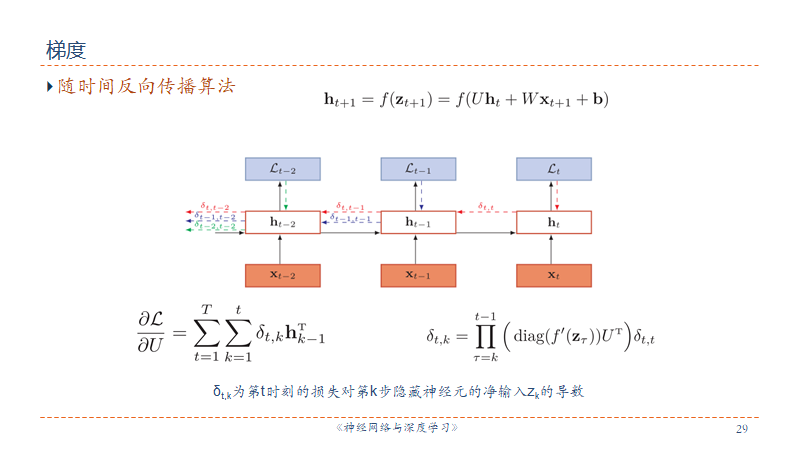
图灵完备是指一种数据操作规则,可以实现图灵机的所有功能,解决所有的可计算问题。
所有的图灵机都可以被一个由使用sigmoid激活函数的神经元构成的全连接循环网络模拟。
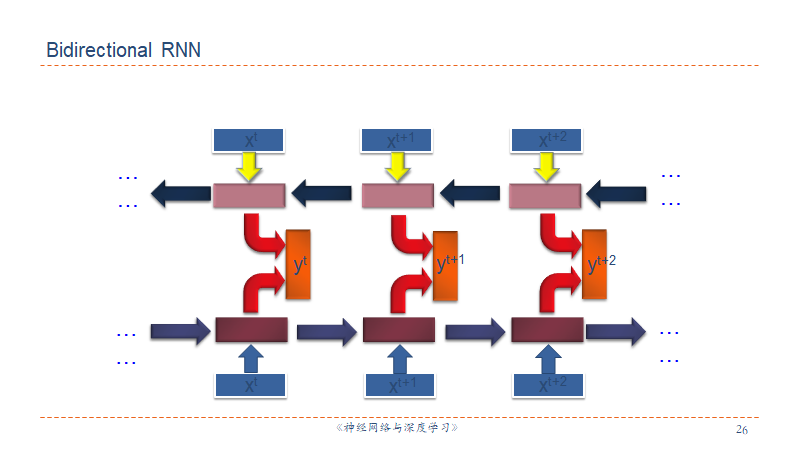
双向RNN就是两个方向的RNN拼起来,一个正着读一个句子(序列),一个倒着读句子,这样每一个节点的输出都是包含了整个句子信息的。
长程依赖问题
梯度爆炸与梯度消失问题,只能学习到短周期的依赖关系。
梯度爆炸
权重衰减(Weight Decay): 是一种正则化技术,旨在限制模型的复杂度。它是通过向模型的损失函数中添加一个正则项来实现的,这个正则项通常是模型权重L2范数的惩罚项。这个惩罚项的作用是让模型权重不要太大,以此来减小模型的复杂度,从而抑制模型的过拟合。
梯度截断:对大于阈值的梯度进行截断(如>15就=15)
梯度消失问题
循环边改为线性依赖:
增加非线性(残差结构):
对于梯度消失的两个结构上的改进,实际就是LSTM做的。LSTM可以缓解梯度消失的问题,但并不能解决梯度爆炸的问题(甚至更厉害,因为更复杂)。关于LSTM梯度爆炸的问题,李宏毅给出的解释是:不同于一般情况下,梯度消失由sigmoid函数导致,RNN中的梯度消失是因为同一个参数被反复用到多次,就好比
, 的微小变化会带来结果的极大变化。LSTM缓解梯度消失的原因则是:细胞记忆,将原来循环边由乘改为加,记忆的影响会一直存在(除非遗忘门发力),记忆更持久。
LSTM
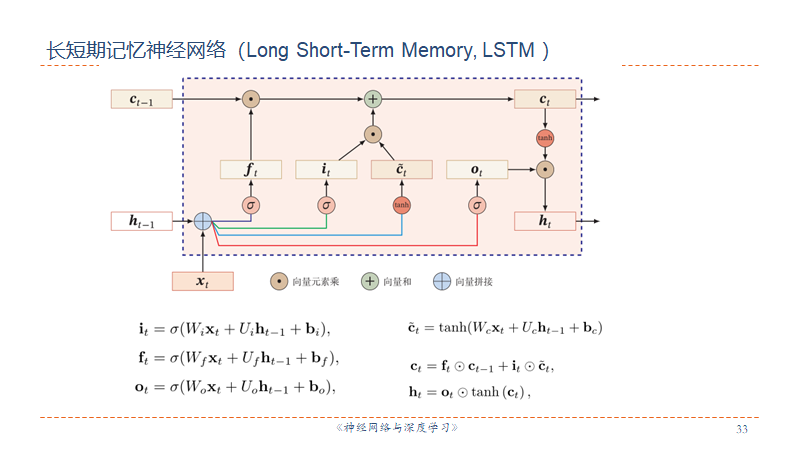
LSTM网络引入门控机制( Gating Mechanism )来控制信息传递的路径。三个“门”分别为输入门
- 遗忘门控制上一个时刻的内部状态
需要遗忘多少信息(保留) - 输入门控制当前时刻的候选状态
有多少信息需要保存(输入) - 输出门控制当前时刻的内部状态
有多少信息需要输出给外部状态
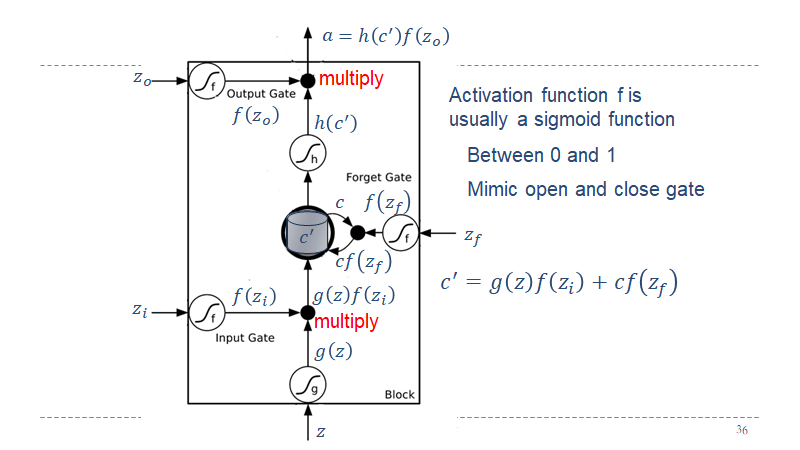
LSTM对比RNN的优点: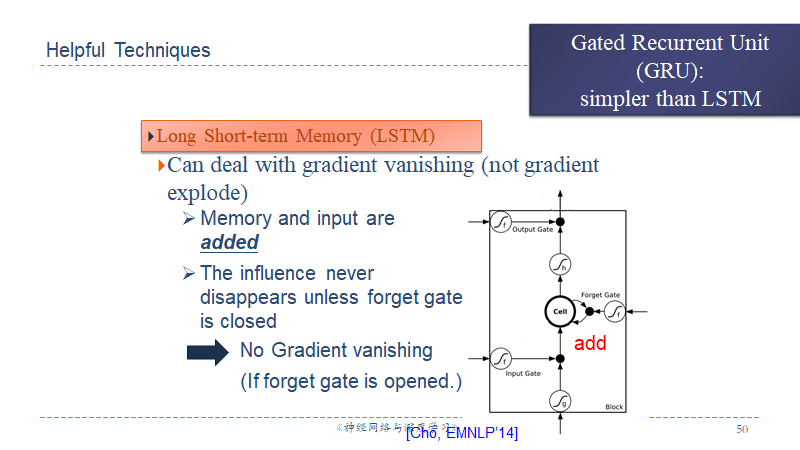
缺点就是梯度仍然爆炸!
RNN的优点:
- 具有记忆功能,可以处理和预测时间序列的数据。
RNN的缺点: - 在处理长序列时,RNN的性能较差,因为信息传播时距离较长时,梯度传播容易出现梯度消失或梯度爆炸的问题。
- RNN的参数更新速度较慢,因为反向传播时需要等待前一时刻的输出结果。
- RNN的模型容量较小,因为信息的传播路径较短,难以捕捉长程依赖信息。
LSTM的优点: - 可以处理长序列信息,因为LSTM通过记忆单元来存储长期依赖信息,信息传播路径较长。
- LSTM的参数更新速度较快,因为记忆单元中存储了长期依赖信息,可以更快地更新参数。
- LSTM的模型容量较大,因为记忆单元中存储了长期依赖信息,可以更好地捕捉序列信息。
LSTM的缺点: - 虽然LSTM可以处理长序列信息,但在处理较短序列时,性能不如RNN。
GRU
Gate Recurrent Unit 的精神是:旧的不去,新的不来。输入和输出门联动,输入打开则输出关闭,输出打开则输入关闭,每次都是置换船新数据。
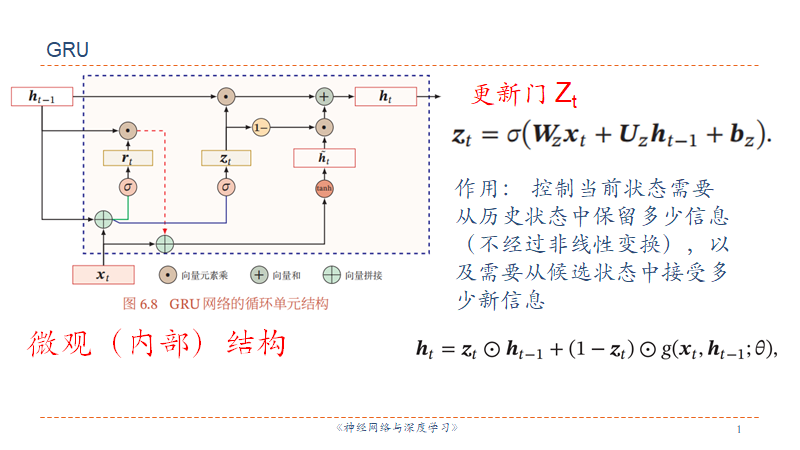

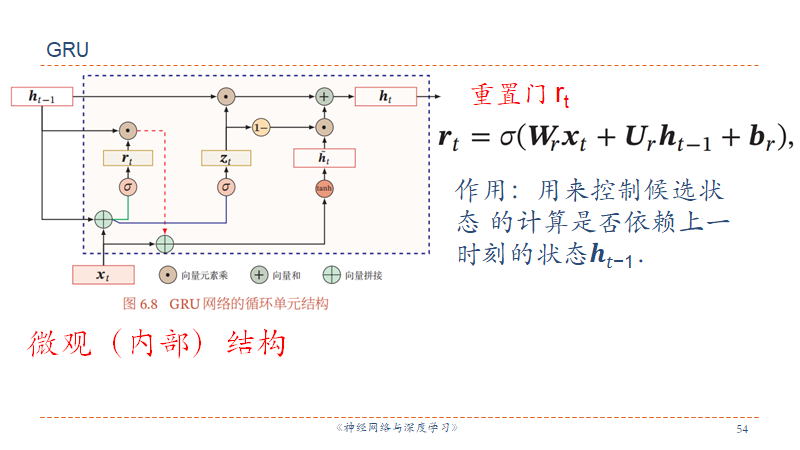

Seq2Seq ???
具体应用:
.png)
公式表达:
同步:.png)
异步:.png)
8. 网络优化
网络优化的难点
结构差异大
没有通用的优化算法
超参数多
非凸优化问题
参数初始化
逃离局部最优
梯度消失、梯度爆炸
低维空间的非凸优化问题:存在一些局部最优点(Local minima)与参数初始化。
高维空间的非凸优化问题(深度神经网络):不在于逃离局部最优点,而在于鞍点。鞍点一阶梯度为0,但海森矩阵非半正定。
在高维空间中,局部最小值(Local Minima)要求在每一维度上都是最低点,这种概率非常低,也就是说,在高维空间中大部分驻点都是鞍点。随机梯度下降对于高维空间中的非凸优化问题十分重要,通过在梯度方向上引入随机性,可以有效地逃离鞍点。
当一个模型收敛到一个平坦的局部最小值时,其鲁棒性会更好,即微小的参数变动不会剧烈影响模型能力;而当一个模型收敛到一个尖锐的局部最小值时,其鲁棒性也会比较差。在训练网络时,没有必要找全局最小值,这反而可能导致过拟合。
神经网络优化的改善方法:
- 优化算法
- 动态学习率调整
- 梯度修正估计
- 参数初始化方法、预处理方法
- 修改网络结构优化地形
- 超参数优化
优化算法

批量大小的影响
批量大小不影响随机梯度的期望,但是会影响随机梯度的方差;
批量大-随机梯度方差小-稳定-较大的学习率
学习率调整
学习率衰减
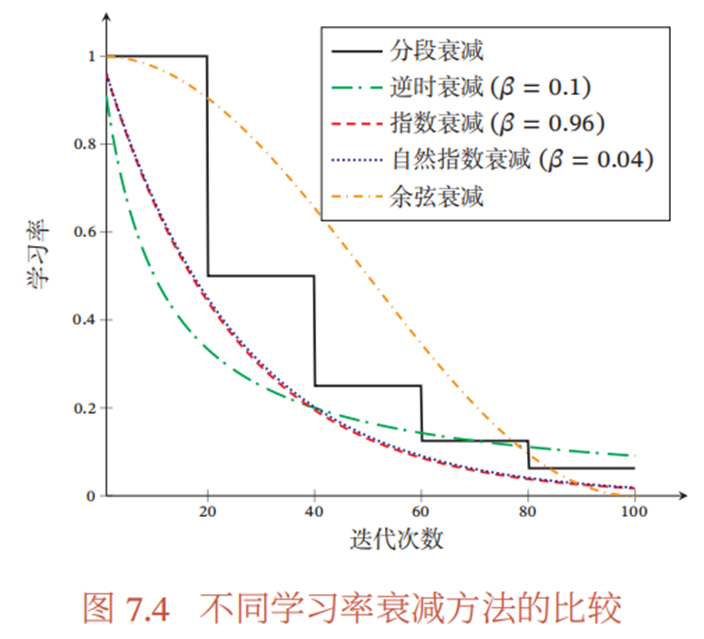
学习率预热
在小批量梯度下降法中,当批量大小的设置比较大时,通常需要比较大的学习率.但在刚开始训练时,由于参数是随机初始化的,梯度往往也比较大,再加上比较大的初始学习率,会使得训练不稳定。因此需要在开始阶段的学习率较小,之后再慢慢恢复(warmup),warmup结束之后,可以使学习率再衰减
其中
周期性学习率调整,包括循环学习率,热重启等,都是在一个周期内先上升后下降,整体是下降,这样能对付尖锐最小值和平坦最小值,找到局部最优解。
自适应学习率调整
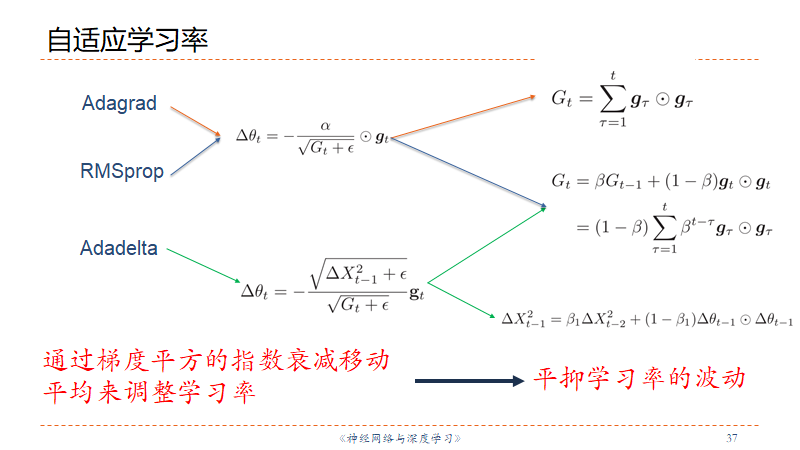
Adagrad有学习率单调下降的问题
RMSProp将
梯度优化
Momentum
其中
每个参数的实际更新差值取决于最近一段时间内梯度的加权平均值,当某个参数在最近一段时间内的梯度方向不一致时,其真实的参数更新幅度变小(训练末期);相反,当在最近一段时间内的梯度方向都一致时,其真实的参数更新幅度变大,起到加速作用(训练初期)。
Nesterov加速梯度
应付唐朝刚的容易引起误解的版本:
真正的版本:
二者的不同在于:Momentum使用的是点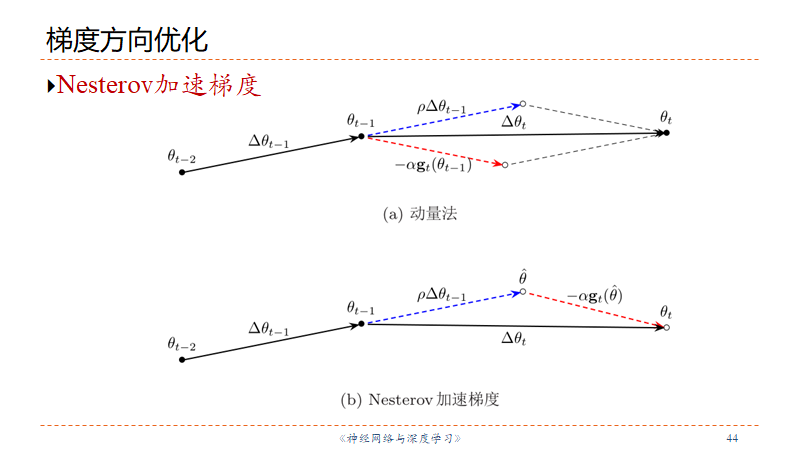
Nesterov一步走完Momentum两步走的路,因此是“加速”。
Adam
Adam ≈ RMSProp + Momentum
- 先计算两个移动平均
- 偏差修正
- 更新
梯度截断
阈值截断
按模截断
参数初始化
- 预训练
- 随机初始化
- 高斯分布(正态)
- 均匀分布
- 固定值初始化
数据预处理
数据归一化
最大最小值归一化 Max-min Normalization
标准化 Standardization
白化与PCA
经过白化处理,特征之间的相关性较低,所有特征具有相同的方差。一个主要的实现方式是PCA
批量归一化与层归一化
计算是这么计算,不过对象不同: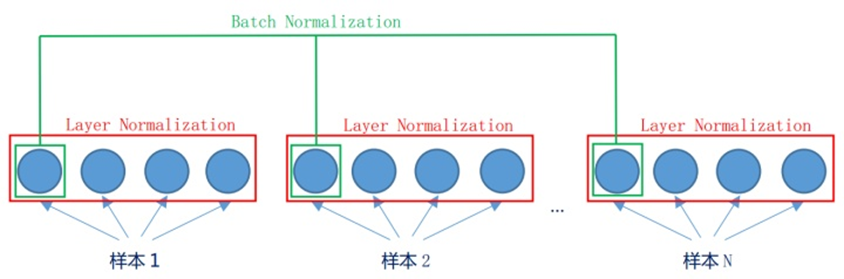
批量归一化在不同样本间做,层归一化在同一样本内做。
批量归一化是不同训练数据之间对单个神经元的归一化,层归一化是单个训练数据对某一层所有神经元之间的归一化
题目
习题7-8 分析为什么批量归一化不能直接应用于循环神经网络.
解答
层归一化是可以用于RNN的,如下显示二者的区别
- 批量归一化是对一个中间层的单个神经元进行归一化操作,因此要求小批量样本的数量不能太小,否则难以计算单个神经元的统计信息(样本太少没有统计学上的意义)
- 如果一个神经元的净输入的分布在神经网络中是动态变化的(如RNN),那么就无法应用批量归一化操作
- 层归一化是对一个中间层的所有神经元进行归一化, RNN可以用层归一化

题目
参考公式如下
解答
- 𝑓(BN(𝑾𝒂(𝑙−1) + 𝒃)) 表示线性计算之后、非线性激活之前(即净输入 𝒛(𝑙))进行 批归一化
- 𝑓(𝑾BN(𝒂(𝑙−1)) + 𝒃) 表示上一层的输出,即当前层线性计算之前进行 批归一化
使用第一种批归一化方式,可以避免线性计算对分布的改变

Dropout
丢弃法:当训练一个深度神经网络时, 我们可以随机丢弃一部分神经元(同时丢弃其对应的连接边)来避免过拟合。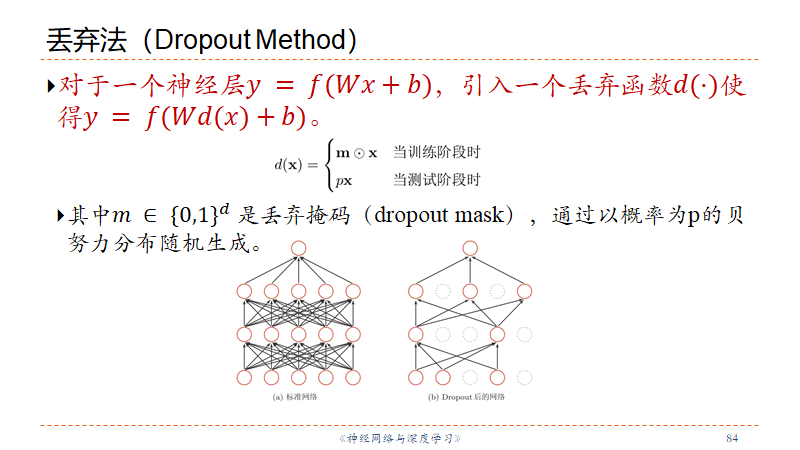
在训练时,激活神经元的平均数量为原来的𝑝 倍.而在测试时,所有的神经元都是可以激活的,这会造成训练和测试时网络的输出不一致.为了缓解这个问题,在测试时需要将神经层的输入𝒙 乘以𝑝,也相当于把不同的神经网络做了平均.保留率𝑝 可以通过验证集来选取一个最优的值.一般来讲,对于隐藏层的神经元,其保留率𝑝 = 0.5 时效果最好,这对大部分的网络和任务都比较有效.当𝑝 = 0.5 时,在训练时有一半的神经元被丢弃,只剩余一半的神经元是可以激活的,随机生成的网络结构最具多样性.对于输入层的神经元,其保留率通常设为更接近1 的数,使得输入变化不会太大.对输入层神经元进行丢弃时,相当于给数据增加噪声,以此来提高网络的鲁棒性.
这张PPT还是错的,邱锡鹏书上是
个子网络,他抄过来就变成2n了😅
贝叶斯的解释的意思是:丢弃法是对参数
变分丢弃法:Dropout应用到RNN上,不应该对循环连接进行丢弃,而应该对非循环连接随机丢弃。对参数矩阵的每个元素进行随机丢弃,并在所有的时刻使用相同的丢弃掩码。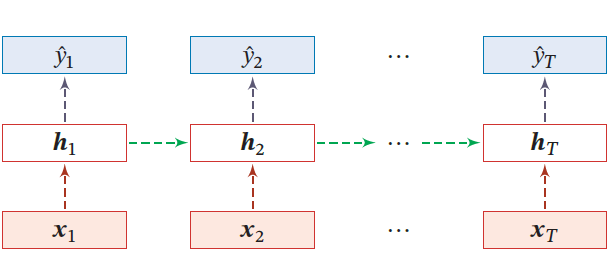
试分析为什么不能在循环神经网络中的循环连接上直接应用丢弃法?
对每个时刻的隐状态进行随机丢弃,会损坏循环网络在时间维度上的记忆能力.
9. 深度强化学习
五要素
强化学习的基本要素包括:
- 状态𝑠 是对环境的描述,可以是离散的或连续的,其状态空间为𝒮.
- 动作𝑎 是对智能体行为的描述,可以是离散的或连续的,其动作空间为𝒜.
- 策略𝜋(𝑎|𝑠) 是智能体根据环境状态𝑠 来决定下一步动作𝑎 的函数.(状态到动作的映射)
- 状态转移概率𝑝(𝑠′|𝑠, 𝑎) 是在智能体根据当前状态𝑠 做出一个动作𝑎 之后,环境在下一个时刻转变为状态𝑠′ 的概率.
- 即时奖励𝑟(𝑠, 𝑎, 𝑠′) 是一个标量函数,即智能体根据当前状态𝑠 做出动作𝑎 之后,环境会反馈给智能体一个奖励,这个奖励也经常和下一个时刻的状态𝑠′ 有关.
马尔科夫过程
马尔可夫过程(Markov Process)是一组具有马尔可夫性质的随机变量序列$𝑠0, 𝑠_1, ⋯,𝑠_𝑡 ∈ 𝒮
马尔可夫决策过程在马尔可夫过程中加入一个额外的变量:动作
其中
⻢尔科夫过程中不存在动作和奖励,马尔可夫决策过程则考虑动作与回报
给定策略
$$\tau = 𝑠0, 𝑎_0, 𝑠_1, 𝑟_1, 𝑎_1, ⋯ , 𝑠{𝑇−1}, 𝑎_{𝑇−1}, 𝑠_{𝑇 }, 𝑟𝑇
其中
强化学习的目标函数就是使回报的期望最大.
基于值函数的学习方法
状态值函数:从状态
$$V^{\pi}(s) =\mathbb E{{\tau \sim p(\tau)} }{[\sum\limits{t=0}^{T-1}\gamma^{t}r_{t+1}\vert \tau_{s_{0}}= s]}$$
一个策略
$$\mathbb E{\tau}{[G(\tau)]} = \mathbb E{{s\sim p(s_0)}}[V^{\pi}(s)]$$
$$V^{\pi}(s) = \mathbb E{{a\sim\pi(a|s) }}\mathbb E{{s’\sim p(s’|s,a) }}[r(s,a,s^\prime)+\gamma V^{\pi}{(s^{\prime})}]=\sum\limits_{a\in A}\pi(a|s)(R_{s}^{a}+{\gamma}\sum\limits_{s’\in S}P_{ss’}^{a}V^{\pi}(s’))$$
想象一个马尔科夫链,方便记忆这个公式. 里面的
Q函数:再详细一些,状态
$$Q^{\pi}(s,a) = \mathbb E{{s’\sim p(s’|s,a) }}[r(s,a,s^\prime)+\gamma V^{\pi}{(s^{\prime})}]=\sum\limits{s’\in S}P_{ss’}^{a}(R_s^a+\gamma V^{\pi}{(s^{\prime})})$$
相当于是把贝尔曼方程中,采取的动作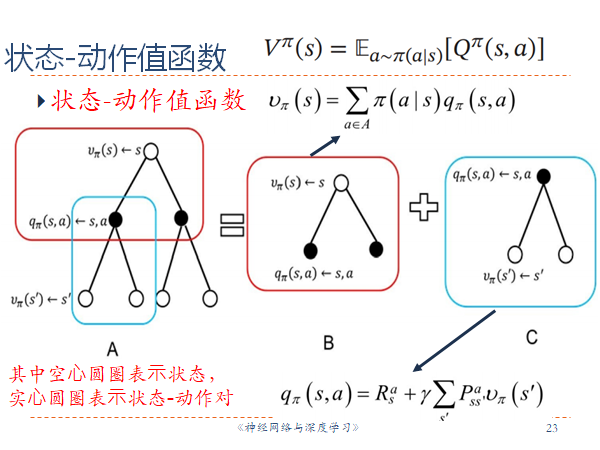
动态规划方法
这两种方法都是基于模型的强化学习(模型相关的强化学习),模型是马尔可夫决策过程(MDP).
两点限制:
- 要求模型已知,即要给出马尔可夫决策过程的状态转移概率𝑝(𝑠′|𝑠, 𝑎)和奖励函数𝑟(𝑠, 𝑎, 𝑠′).但实际应用中这个要求很难满足(对策:随机游走探索环境)
- 状态空间大,效率极低(对策:神经网络近似计算V(深度置信Q网络))
策略迭代
策略迭代包含策略评估(计算
值迭代
相当于是只迭代
蒙特卡罗方法
蒙特卡罗(采样)方法:状态转移概率𝑝(𝑠′|𝑠, 𝑎)和奖励函数𝑟(𝑠, 𝑎, 𝑠′)未知,MDP模型崩塌(模型无关的强化学习),需要通过采样来计算Q函数.
$$Q^{\pi}(s,a) = \frac{1}{N}\sum\limits_{n=1}^{N}G(\tau^{n}{s_0=s,a{0=a}})$$
Q函数通过N次实验轨迹的平均回报来近似。
时序差分法
是一种同策略方法。
蒙特卡罗方法需要一条完整的路径才能知道其总回报,也不依赖马尔可夫性质;而时序差分学习方法只需要一步,其总回报需要通过马尔可夫性质来进行近似估计.
Q-Learning
是异策略的时序差分法。
与SARSA 算法不同,Q学习算法不通过
演员评论家

10. 20级真题
问答题
1. CNN计算
输入图片97*97*3,15个9*9的滤波器,无0填充,滑动步长为2.
(1) 计算输出图像的尺寸 (5分)
(2) 该卷积层的参数量(5分)
(3)CNN的特点(5分)
2.自注意力机制
······ChatCPT·····马斯克·······危险的AI······
(1) 自注意力的模式结构图 (5分)
(2) 如果使用点积计算相似度,给出自注意力的完整计算过程 (10分)
3.解释定理
分别解释没有免费午餐定理和丑小鸭定理 (10分)
4. 优化算法
阐述动量法和Nesterov加速梯度(10分)
5. 优化算法
解释高低维度下,参数优化的难点与侧重点(10分)
简答题
- 描述SGD算法,并写出优缺点 (10分)
- LSTM是对RNN的改进,能否解决梯度消失与梯度爆炸问题,请阐述原理(15分)
论述题
….小鹏汽车G6自动驾驶很厉害….假如你是小鹏的算法工程师,请利用深度强化学习对小鹏汽车的人机对话系统建模,列举强化学习的五要素,并给出最大化奖励函数的算法。(15分)
没错,深度强化学习的对话系统;