第1章 认识数据挖掘 数据挖掘的定义 技术角度:利用计算机技术,从数据中自动分析并提取信息的处理过程;目的是发掘数据中潜在的有价值 的信息;一般使用机器学习、统计学、模式识别等多种方法来实现。
有指导学习和无指导学习
机器学习中的基本方法有:概念学习、归纳学习、有指导学习和无指导学习。
有指导学习 :通过对大量已知分类或输出的实例进行训练,调整分类模型的结构,达到建立准确分类或预测位置模型的目的;这种基于归纳的概念学习过程被称为有指导学习。无指导学习 :在学习训练之前,无预先定义好分类的实例。数据实例按照某种相似度度量方法,计算相似程度 ,将最为相似的实例聚类在一个簇中,再解释和理解每个簇的含义,从中发现聚类的意义。(K-Means,凝聚聚类,概念分层Cobweb,EM算法)
数据挖掘的过程 四个步骤:
准备数据,包括训练数据和检验数据;
选择一种数据挖掘技术或算法,将数据提交给挖掘软件;
解释和评估模型;
模型应用;选择技术与算法需要考虑 :
判断学习是有指导还是无指导的;
数据集中怎样划分训练、测试、检验数据;
如何设置数据挖掘算法的参数;
数据挖掘的作用(种类分类,非技术)
第2章 基本数据挖掘技术 决策树
1、决策树概念和C 4.5算法的一般过程
概念 决策树是一个树状结构的模型,每个节点表示对象的某个属性,分支表示属性的某个可能取值,叶节点的取值就是决策树的输出结果。
C4.5算法 (1)给定一个表示为“属性-值”格式的数据集T。数据集由多个具有多个输入属性和一个输出属性的实例组成。
该子类中的实例满足预定义的标准,如全部分到一个输出类中,或者分到一个输出类中的实例达到某个比例;
没有剩余属性。
关键技术 选择最能区分实例属性的方法 优先选择具有最大增益率的属性 来使数据的概化程度最大(层次和节点数最小)。信息熵 信息增益 出 现 在 类 中 的 数 量 实 例 总 数 出 现 在 类 中 的 数 量 实 例 总 数 出 现 在 类 中 的 实 例 个 数 所 有 实 例 总 数 类 出 现 在 类 中 的 实 例 个 数 所 有 实 例 总 数 出 现 在 类 中 的 实 例 个 数 所 有 实 例 总 数
剪枝方法 检验方法
决策树规则 将决策树翻译成规则,计算正确率与覆盖率;
IF Courses <≤5 and Weather = Rain THEN Play = No
正确率:3/5 = 60% 覆盖率:3/8 = 37.5%
正确率:满足整句/满足前半句 覆盖率:满足整句/满足后半句优缺点(了解) 优点
关联规则 Apriori算法的基本思想
生成条目集。条目集是符合一定的支持度 要求的“属性-值”的组合。那些不符合支持度要求的组合被丢弃,因此规则的生成过程可以在合理的时间内完成。
使用生成的条目集依据置信度 创建一组关联规则。
关联规则及其置信度和支持度 支持度:满足整句/满足后句
在实际使用时,依次生成单项、双项、三项条目集,以生成的条目集为基础创建关联规则。
以双项条目集中的第一条条目生成的两条规则——
IF Book =1 THEN Earphone = 1 (置信度:4/5 = 80%,保留)
IF Earphone = 1 THEN Book =1(置信度:4/7 = 57.1%,删除)
以三项条目集中的第一条条目生成的三条规则——
IF Book =1 & Earphone = 1 THEN DVD = 1(置信度:4/4 = 100%,保留)
IF Book =1 & DVD = 1 THEN Earphone = 1(置信度:4/4 = 100%,保留)
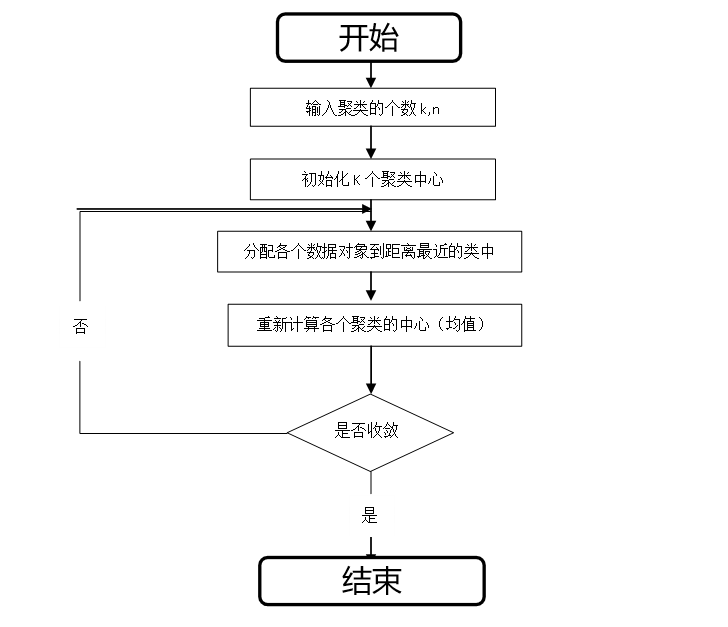
IF Earphone = 1 & DVD = 1 THEN Book =1(置信度:4/6 = 66.7%,删除)聚类技术 K-means算法的基本思想
随机选择一个K值,用以确定簇的总数。
在数据集中任意选择K个实例,将他们作为初始的簇中心。
计算这K个簇中心与其他剩余实例的简单欧式距离。用这个距离作为实例之间相似性的度量,将与某个簇相似度高的实例划分到该簇中,成为其成员。
使用每个簇中的实例来计算新的簇中心。
如果得到的新的簇中心等于上次迭代的簇中心,终止算法。否则,用新的簇中心重复3~5.
K-means聚类分析实例 优缺点 优势数值型 数据,若数据集中有分类类型的属性,要么将该属性删除,要么将其转换成等价的数值数据。簇个数 (带有随意性,错误的选择将影响聚类效果)。通常选择不同的K值进行重复实验,期望找到最佳K值。大小近似相 等时,K-means算法的效果最好。属性进行选择 。簇的解释困难 。可使用有指导的挖掘工具对无指导聚类算法所形成簇的性质作进一步的解释。
第3章 数据库中的知识发现 KDD的定义(了解) Knowledge Discovery in Data,从数据集中提取可信的、新颖的、具有潜在价值的、能被人理解的、非繁琐的处理过程(大部分步骤由系统自动执行)。
KDD过程模型 经典模型 CRISP-DM商业模型 联机模型OLAM 数据预处理:直方图归约、数据规范化和数据平滑 分箱法: (噪声处理->数据平滑)数据排序 ==,如3,6,12,22,24,26,27,30,30
直方图规约
数据标准化
最小-最大缩放 (Min-Max Scaling):将数据缩放到0-1之间的范围,通过对原始数据进行线性变换来实现。具体来说,最小-最大缩放将原始数据v缩放到新的取值范围v’,计算公式为
Z-score标准化(Z-score normalization):将数据缩放为均值为0、标准差为1的分布,使得数据分布在以0为均值,1为标准差的正态分布中。具体来说,Z-score标准化将原始数据x标准化为新的取值范围y,计算公式为y = (x - μ) / σ,其中μ和σ分别是原始数据的均值和标准差。
小数定标标准化 (十进制缩放)(Decimal scaling):通过移动小数点的位置,将数据缩放到[-1,1]或[-0.5,0.5]之间的范围。具体来说,小数定标标准化将原始数据x乘以10的k次方,得到新的取值范围y,计算公式为y = x / 10^k,其中k是满足10^(k-1) ≤ |x| < 10^k的整数。根据最大值决定移动的位数。
对数标准化是一种将数据转换为对数的数据预处理方法,常用于将非负数数据进行平滑处理,使其更易于比较和分析。具体来说,对数标准化将原始数据x取对数,得到新的取值范围y,计算公式为y = log(x)。
归一化(Normalization):将数据缩放到单位长度或者单位范围内,常用的归一化方法包括L1范数归一化和L2范数归一化。具体来说,L1范数归一化将原始数据x缩放为新的取值范围y,计算公式为y = x / (|x1| + |x2| + … + |xn|);L2范数归一化将原始数据x缩放为新的取值范围y,计算公式为y = x / sqrt(x1^2 + x2^2 + … + xn^2)。
第5章 评估技术 评估分类类型输出模型
真正例
真反例
预测正例
TP
FP
预测反例
FN
TN
正 确 率
错 误 率
查 准 率
查 全 率
评估数值型输出模型
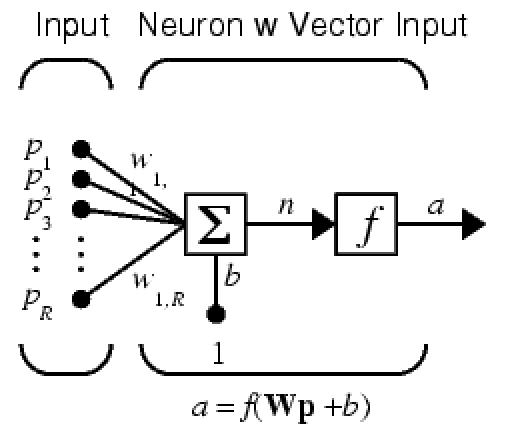
第6章 神经网络 人工神经元模型
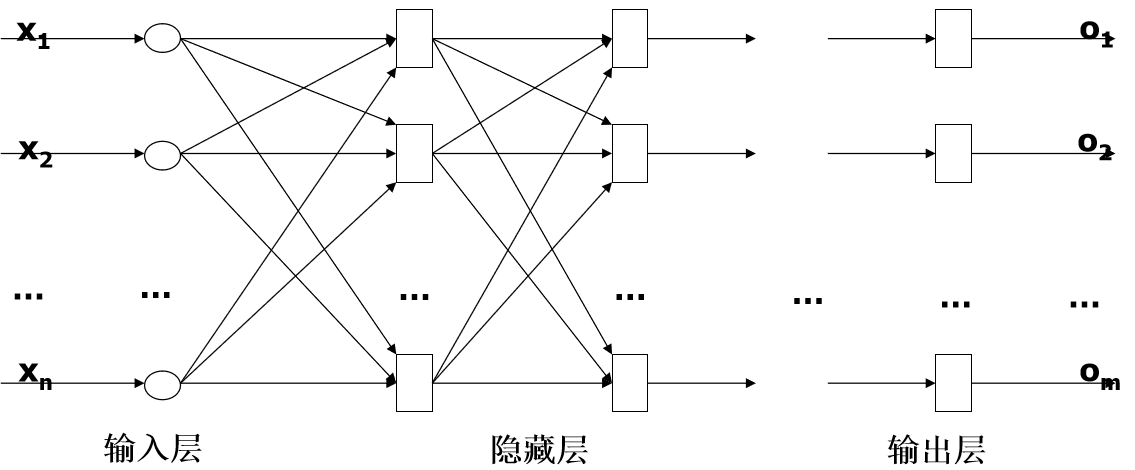
BP神经网络 BP神经网络结构,前向计算过程
BP算法的一般过程 B-P算法的学习过程如下:
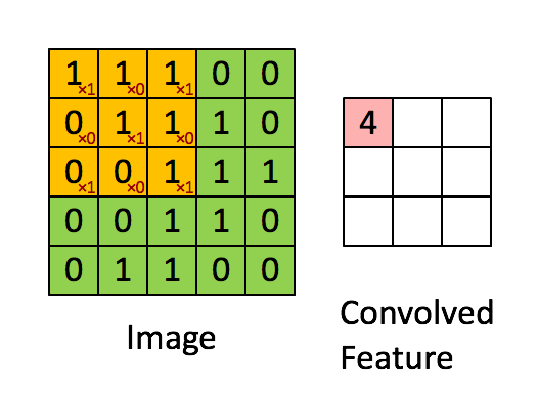
CNN 卷积 局部感受野 。因为在一个图像中,距离较近的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。权值共享 。统计特性 与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征 。对特征进行识别 ,而不考虑它在可视域中的位置。自由变量的个数 。通过控制模型的规模,卷积网络对视觉问题可以具有很好的泛化 能力。
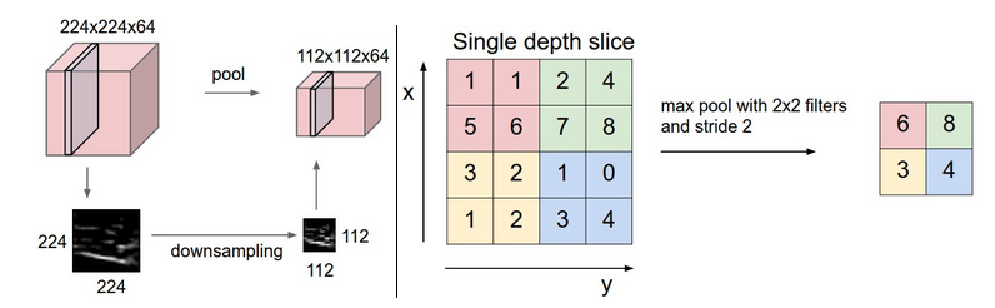
池化/采样
第7章 统计技术 回归分析 回归分析是一种统计分析方法,用来确定两个或两个以上变量之间的定量的依赖关系,并建立一个数学方程来概化一组数值数据。最小二乘法
贝叶斯分析 一种参数估计方法,将关于未知参数的先验信息与样本信息结合(列表),根据贝叶斯公式,计算条件概率,得出后验信息,从而推断未知参数;
概率为0–加小常数
数据缺失–简单忽略,概率记为1
聚类技术
聚类有划分聚类(K-Means)、分层聚类(凝聚、分裂)、模型聚类(EM算法)三大种;
凝聚聚类算法
Cobweb分层聚类 算法 :
建立一个类,使用第一个实例作为它的唯一成员;
对于剩余实例。在每个树层次(概念分层)上,用评价函数决定执行下列动作之一:
将新的实例放到一个已存在的簇中;
创建一个只有这个新实例的新概念簇;
CU值的计算:
优势:能够自动调整类(簇)的个数,不会因为随机选择分类个数的不合理性而造成聚类结果的不理想。
对实例顺序敏感,需要引入两种附加操作——合并和分解降低敏感性。
假设每个属性的概率分布是彼此独立的,而实际这个假设不总是成立;
类(簇)的概率分布的表示、更新和存储的复杂程度,取决于每个属性取值个数。当属性取值较多时,算法的时间和空间复杂度会很大。
偏斜的实例数据会造成概念分层树的高度不平衡,也会导致时间和空间复杂度的剧烈变化。